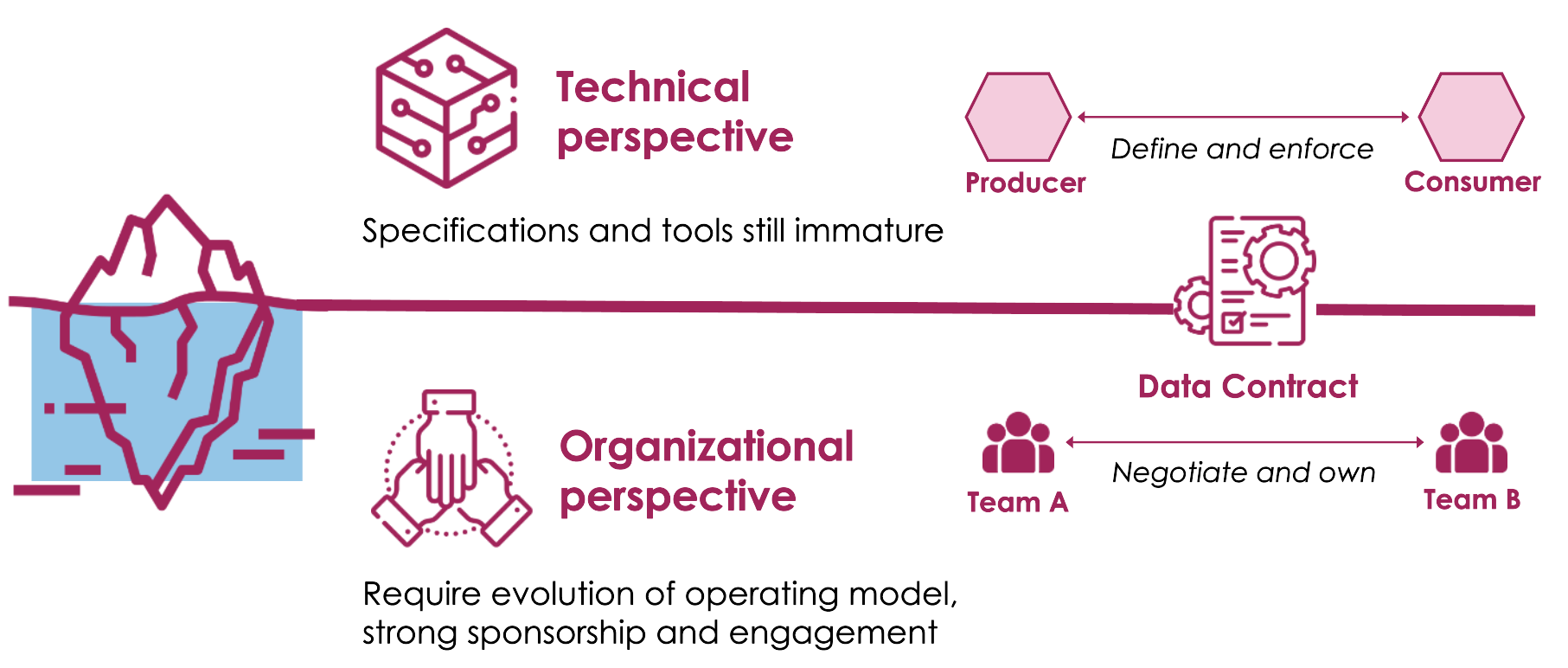
Data Contracts are agreements between data producers and data consumers aimed at regulating both the data and their exchange. They provide transparency on data dependencies and usage within an information architecture and help ensure consistency, clarity, reliability, and quality.
A data contract allows answering fundamental questions about the data, such as:
• How often are these KPIs updated?
• Are these data reliable?
• Where and how can I access this information?
• What is the expected usage for this data?
• Who has permission to view this value?
• What does this attribute mean?
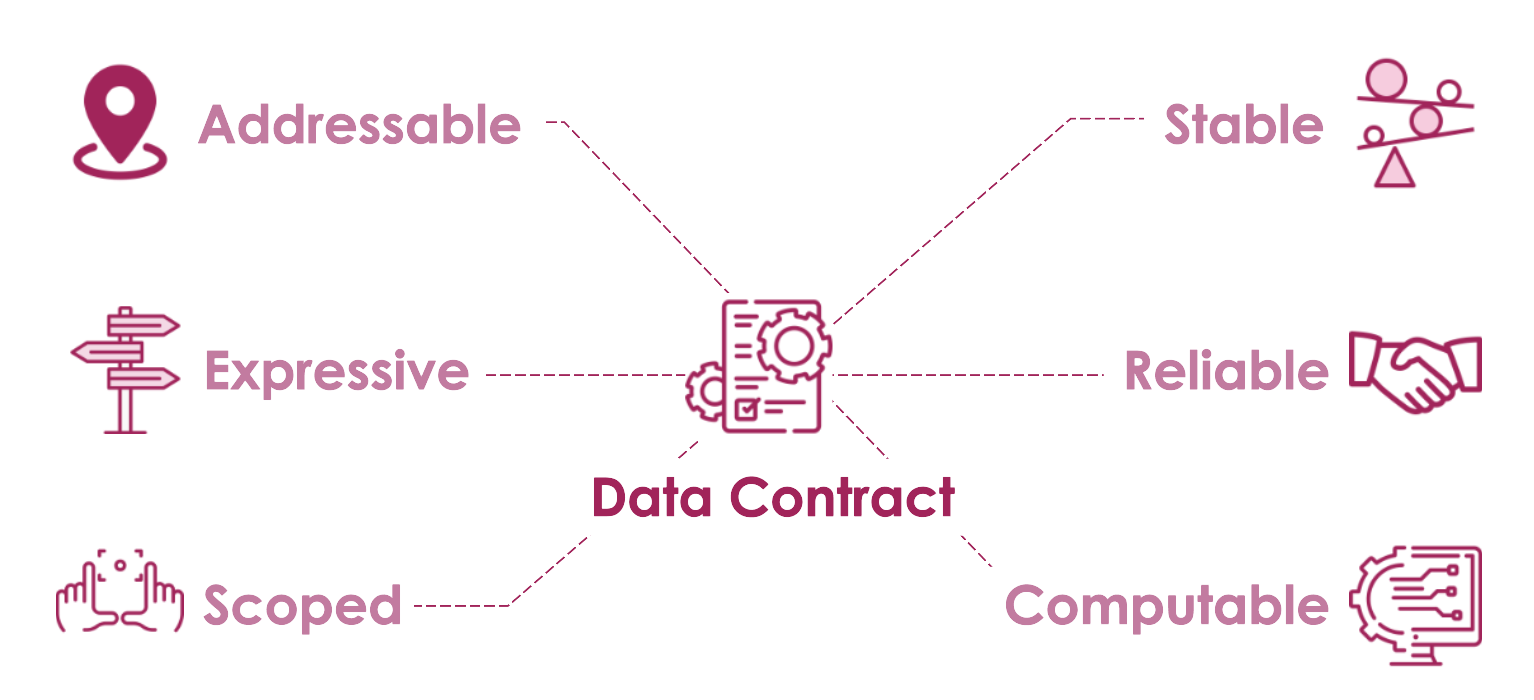
Every data contract must meet the following characteristics:
• Addressable: It needs to be easily identifiable for usability
• Expressive: Self-descriptive, defined clearly and unequivocally
• Scoped: With a clear scope that suits its purpose, to prevent misuse, ambiguity, or excessive cognitive load on those responsible
• Stable: Unchanged for reasonable time intervals; the measures for managing any changes are also part of the data contract
• Reliable: It must be respected by all involved parties
• Computable: Ideally, it should be processable through automation services. However, it typically evolves gradually from contracts intended as human-readable documentation to data contracts as code designed for use
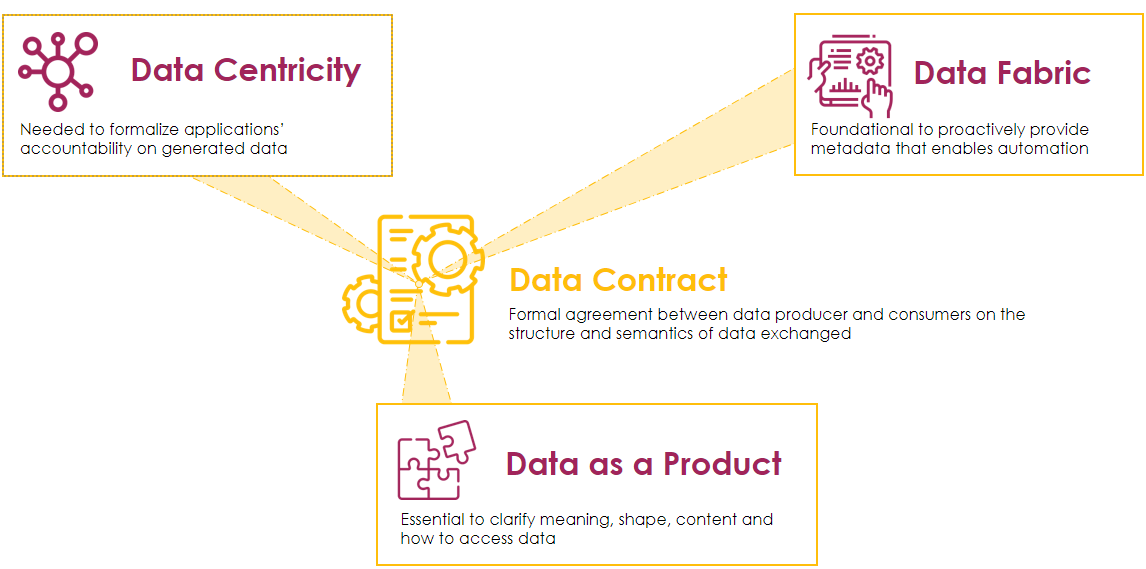
Data contracts are in the spotlight as they sit at the intersection of 3 key trends in data management: Data Centricity, Data as a Product, and Data Fabric:
• According to the data-centric manifesto, applications should not be at the center of architecture; data should be. While applications generate and consume data, they shouldn’t treat it as a byproduct but should be responsible for it, and contracts are a good way to formalize this responsibility.
• Focusing on the mesh principle of Data as a Product, it’s crucial for developed assets to have clear interfaces to their consumers formally specifying scope, provided services, and how to access them: this is exactly what data contracts are designed for.
• The Data Fabric paradigm emphasizes automation and reproducibility in data management and heavily relies on metadata collection and activation: data contracts serve as a primary and proactive source of metadata.
In databases and data warehouses, schema-based data management has been the norm for decades: data undergo rigorous analysis, are divided by domain, modeled, and documented. However, their behavior is typically governed by local constraints that do not consider their dissemination and evolution. This approach often leads to a lack of flexibility and adaptability. Long chains of dependencies are often created without guarantees, such as rules for introducing changes or characteristics of information exposed by an artifact. This approach often results in unexpected surprises when a schema modification can collapse the entire data pipeline.
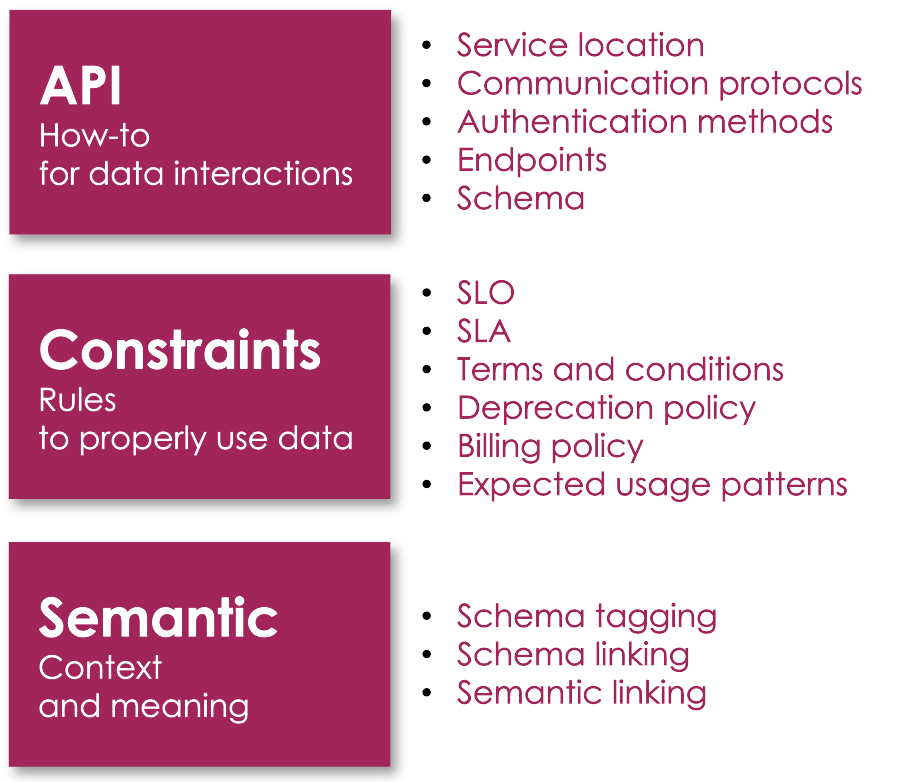
Data contracts are often misunderstood and reduced to simple schemas, the physical representation of data. However, schemas serve as the basis for data contracts; they are their primary aspect but do not capture their entire essence. The fundamental elements of a data contract include:
• API: to describe how to access and consume exposed data. A robust API provides details on service location, supported communication protocols, authentication methods, available endpoints, and data exchange schemas.
• Constraints: to define engagement rules, describing how data is exchanged and how it should be used. They establish the perimeter within which the data contract operates.
• Semantics: to clarify the meaning of exchanged data. This aspect is crucial; however, its formalization is still an ongoing challenge.