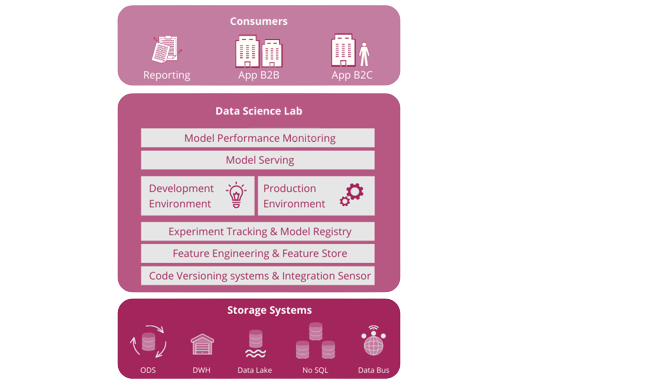
In a modern data-driven company, data represents a fundamental asset and all actions and strategic directions are dictated by the insights gained from the analysis of data coming from a multitude of different sources.
Data science represents the set of methods, processes, algorithms and technologies that enable the extraction of useful knowledge from the multitude of structured and unstructured data that the company has at its disposal within the data warehouse, data lake or, more generally, the data platform.
In this way, artificial intelligence (AI) and machine learning (ML) techniques are redefining entire market sectors, from the world of online retail to transport services, from domotics to the insurance and banking fields, enabling the understanding of correlations and trends concerning complex phenomena such as consumer preferences, the evolution of demand for a specific product or service, and the analysis of market competition.
Over the last ten years, these technologies have spread not only in big companies, but increasingly also in SMEs; both have dedicated these years to experimentation, alternating between promising results and costly failures.
-
Industries
Le industries con cui collaboriamo: rispondiamo a qualsiasi sfidaVEDI TUTTE LE INDUSTRIES
-
Solutions
Le nostre Solutions: per estrarre il massimo valore dai datiVEDI TUTTE LE SOLUTIONS
-
Technologies
Le nostre tecnologie: non abbiamo paura delle sfideVEDI TUTTE LE TECHNOLOGIES