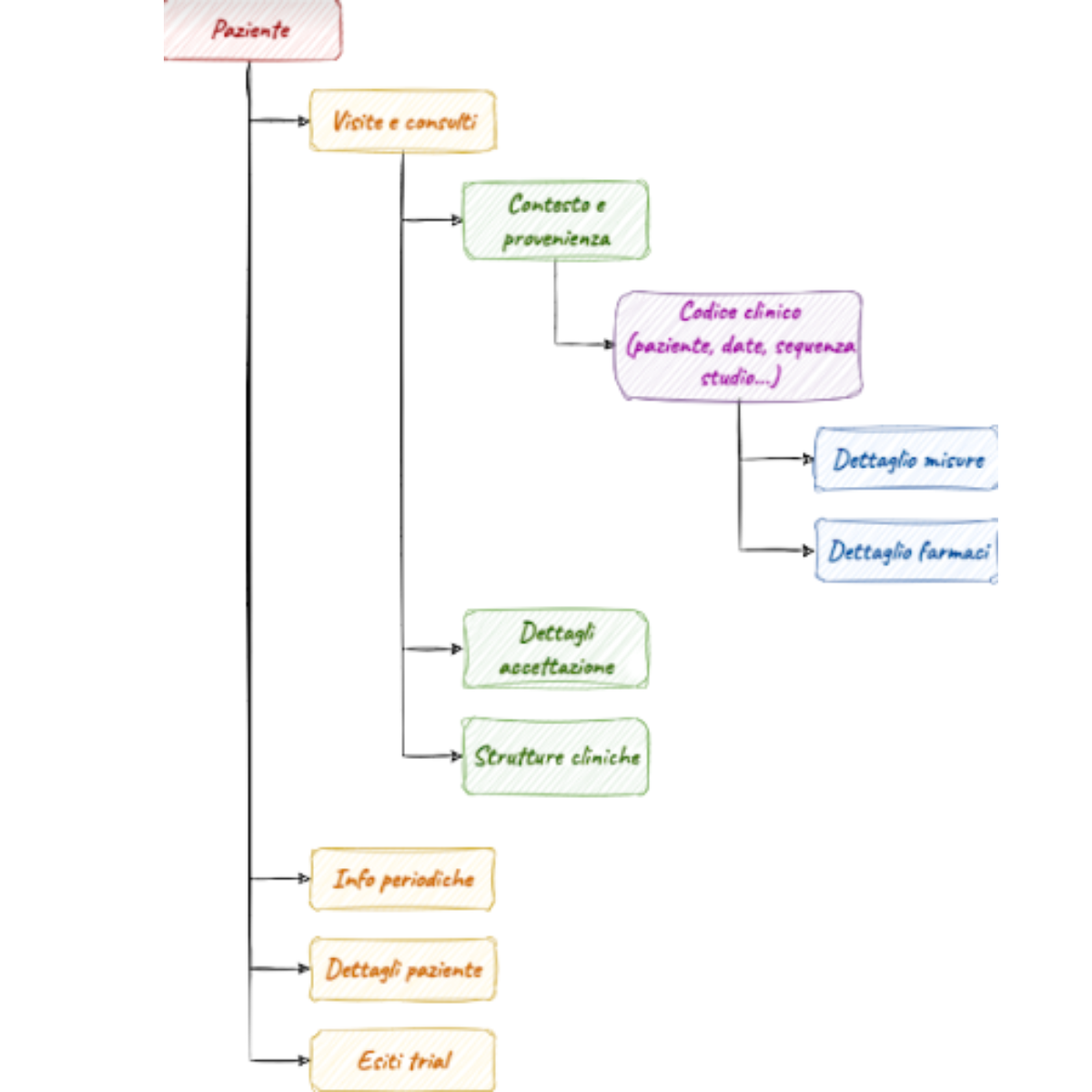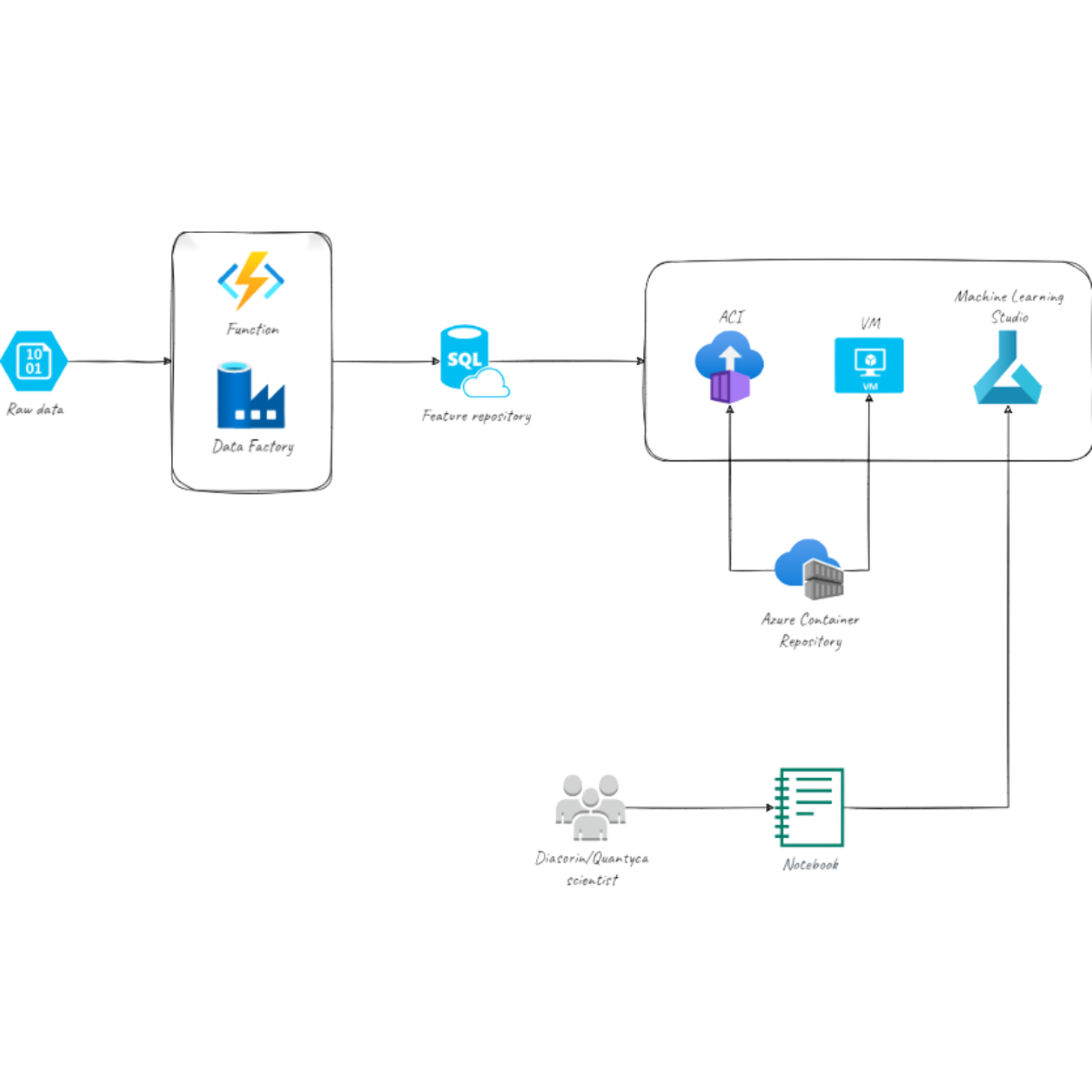
Da oltre 50 anni Diasorin sviluppa, produce e commercializza kit di reagenti per la diagnostica di laboratorio in tutto il mondo attraverso 45 società, 4 divisioni, 10 siti produttivi e 9 centri di ricerca e sviluppo. Questa organizzazione consente a Diasorin di avere un’ampia offerta di test diagnostici e soluzioni di tecnologia su licenza, resa disponibile grazie ai continui investimenti nella ricerca. La varietà dell’offerta e gli investimenti in ricerca ed innovazione qualificano Diasorin nel proprio mercato come il player con la più ampia gamma di soluzioni specialistiche del settore e identifica il Gruppo come lo “Specialista della diagnostica”.
-
Industries
Le industries con cui collaboriamo: rispondiamo a qualsiasi sfidaVEDI TUTTE LE INDUSTRIES
-
Solutions
Le nostre Solutions: per estrarre il massimo valore dai datiVEDI TUTTE LE SOLUTIONS
-
Technologies
Le nostre tecnologie: non abbiamo paura delle sfideVEDI TUTTE LE TECHNOLOGIES