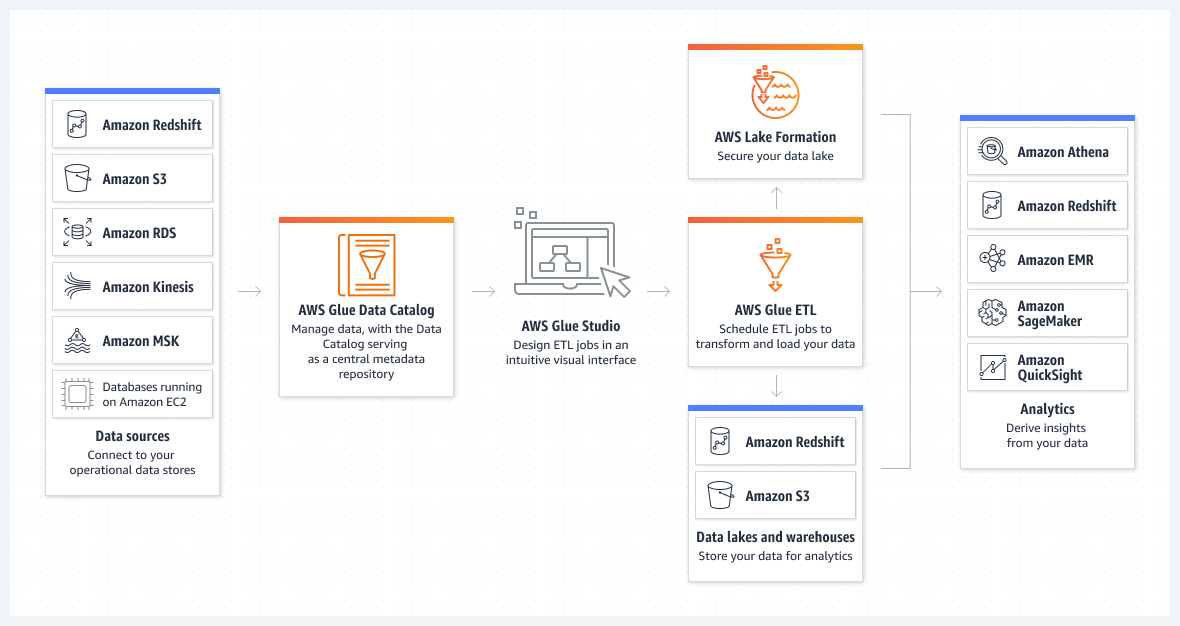
AWS Glue consolida le principali funzionalità di integrazione dei dati in un singolo servizio serverless. Le funzionalità principali includono:
- Data Classification
Funzione che tramite crawlers permette di determinare lo schema tecnico dei dati. AWS Glue fornisce classificatori per i tipi di file più comuni, ad esempio CSV, JSON, XML, AVRO. Fornisce inoltre classificatori per i più comuni sistemi di gestione di database relazionali utilizzando una connessione JDBC.
- Data Catalog
Archivio di metadati persistente: il catalogo contiene definizioni di tabelle, definizioni di processi e altre informazioni di controllo per la gestione delle entità dati in AWS.
- ETL/ELT
AWS Glue Jobs system fornisce un’infrastruttura gestita per la definizione, la pianificazione e l’esecuzione di operazioni ETL/ELT sui dati al fine di prepararli e consolidarli e permetterne l’analisi.
- Streaming Processing
È possibile, oltre alle modalità batch, creare operazioni di streaming processing che vengono eseguite continuamente, ad esempio consumando dati da Apache Kafka, Amazon Kinesis Data Streams e Amazon Managed Streaming for Apache Kafka (Amazon MSK).