Lo streaming di dati, a differenza dei paradigmi di integrazione basati su flussi batch o API che si concentrano prevalentemente sullo stato delle entità di business trattate, si concentra sulla raccolta, gestione e scambio di eventi tra applicazioni e sistemi.
Un evento descrive un cambiamento che è avvenuto, in uno specifico momento nel tempo, nello stato di un’entità di interesse. Poiché a partire dagli eventi di modifica è sempre possibile ricostruire lo stato di un’entità, i sistemi di streaming permettono di trasferire in modo asincrono e altamente scalabile lo stato delle applicazioni tra i sistemi interessati.
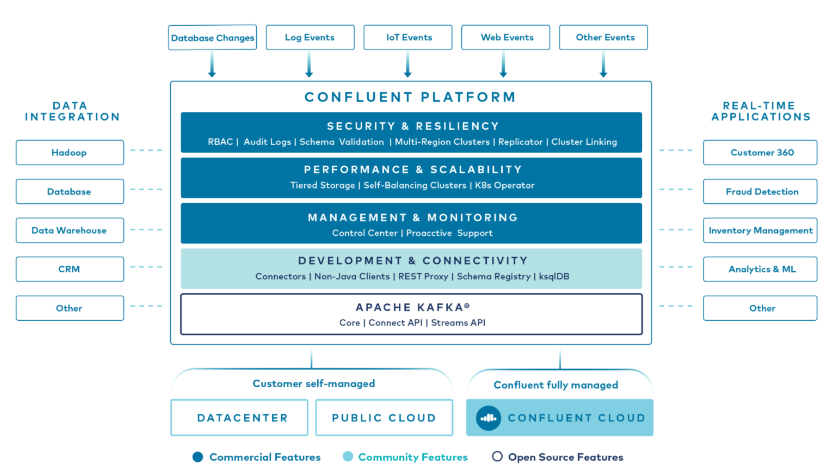
Kafka è una delle piattaforme più utilizzate al mondo per gestire dati in streaming e realizzare integrazioni di dati in real time. La piattaforma Confluent, la cui società è stata fondata dai creatori di Kafka, ne espande i vantaggi con funzionalità di livello enterprise riducendo il TCO e facilitando gestione e utilizzo.
Riteniamo fondamentale valutare la componente real-time sin dall’inizio nella realizzazione di nuovi use case, infatti da questa si possono sempre derivare subset e snapshot di dati per le diverse tipologie di consumo, siano esse in real-time o batch. Al contrario un flusso di dati gestito in modalità batch non potrà produrre in uscita un flusso continuo di dati. Questa tipologia di flussi viene privilegiata perchè solitamente si ha la percezione che realizzare flussi in real-time sia più complesso della gestione di batch di dati, ignorando però che la loro futura evoluzione (che può essere richiesta in seguito a un cambio di requisiti) tipicamente richiede effort e costi superiori rispetto ad un ulteriore sforzo iniziale per il trattamento di stream di dati.
La maggior velocità nelle integrazioni garantita dalle architetture basate sullo streaming fornisce un importante vantaggio competitivo in termini di soddisfazione degli utenti ed efficacia delle azioni intraprese a fronte di ciò che accade. La nostra concezione delle streaming platform non prevede soltanto la loro alimentazione da parte delle fonti dati operazionali per il consumo da parte di sistemi operazionali e analitici, caso d’uso standard, ma è aperta anche alla raccolta di informazioni da sistemi analitici (ad esempio raccogliendo l’output di un modello di machine learning) e alla loro propagazione verso i sistemi operazionali.
Si pensi a titolo di esempio a quanto sia importante, in uno scenario omnicanale, poter allineare in tempo reale negozio fisico ed e-commerce o fornire raccomandazioni personalizzate al cliente quando è ancora in negozio o sul sito e non il giorno dopo oppure ancora a individuare le frodi contestualmente alle transazioni bancarie e non a posteriori.