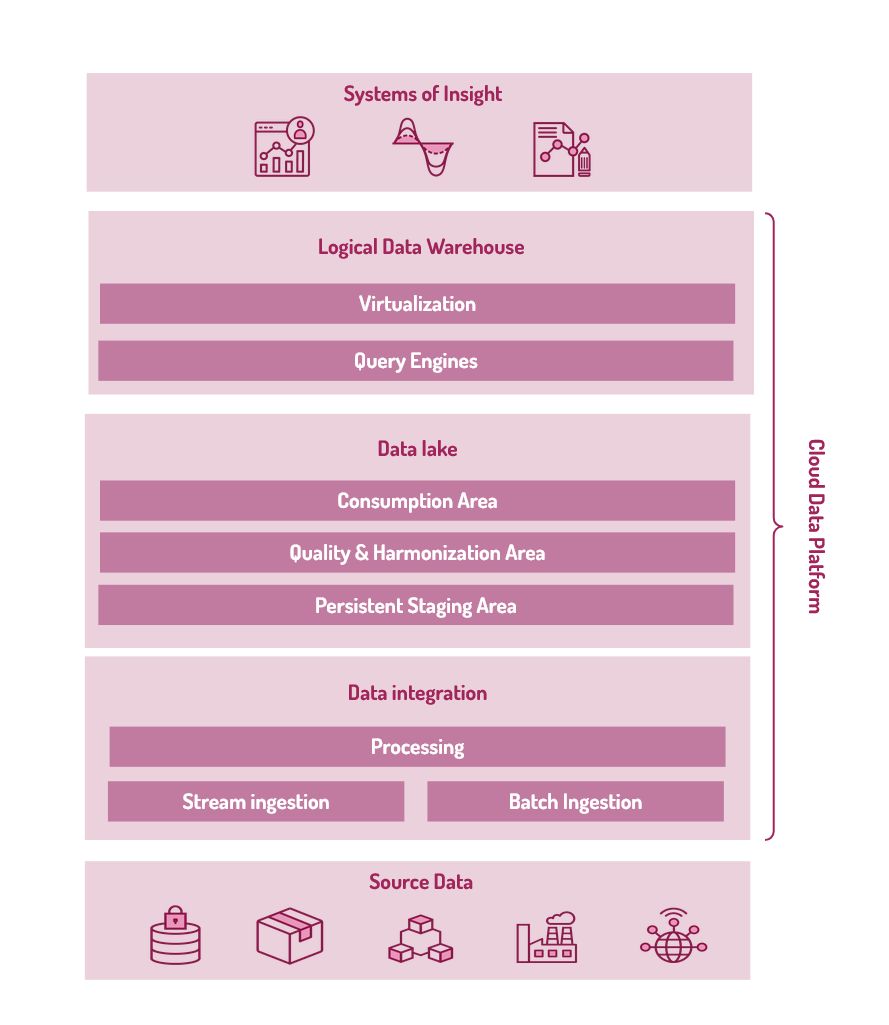
La possibilità di scalare in modo elastico risorse di storage e computazione unitamente al modello di tariffazione a consumo rende il Cloud l’ambiente ideale per progettare moderne data platform capaci di superare i limiti tradizionali di data warehouse e data lake on premises.
Per questo motivo i workload di integrazione, storage a analisi dati sono tra i primi use case attivati nei percorsi di cloud transformation di molte aziende.
E’ tuttavia necessario, per poter sfruttare a pieno il Cloud al fine di aumentare l’agilità dello sviluppo riducendo al contempo i costi di gestione, ripensare l’architettura delle data platform.