Nella moderna azienda data driven, i dati rappresentano un asset fondamentale e tutte le azioni e le direzioni strategiche sono dettate dagli insight ricavati dall’analisi dei dati che arrivano da una molteplicità di fonti diverse.
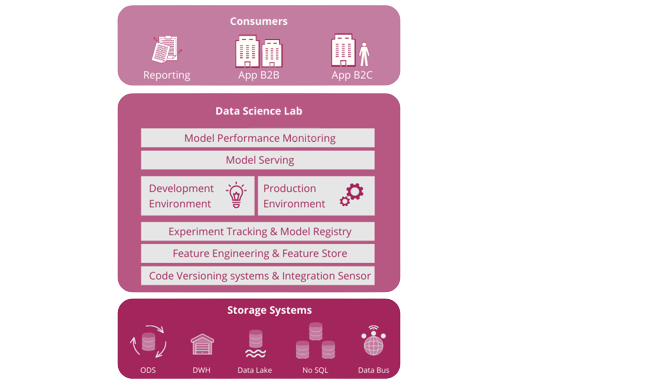
La data science rappresenta l’insieme di metodi, processi, algoritmi e tecnologie che consentono di estrarre la conoscenza utile dalla moltitudine di dati strutturati e non strutturati, che l’azienda ha a disposizione all’interno del data warehouse, data lake o, più in generale, della data platform.
Le tecniche di intelligenza artificiale(AI) e machine learning(ML) stanno in questo senso ridefinendo interi settori di mercato, dal mondo del retail online ai servizi di trasporto, dalla domotica,al campo assicurativo e bancario, permettendo di comprendere correlazioni e andamenti riguardanti fenomeni complessi come le preferenze dei consumatori, l’evoluzione della domanda di uno specifico prodotto o servizio e le analisi della concorrenza sul mercato.
Negli ultimi dieci anni queste tecnologie si sono diffuse non solo nelle big company, ma in modo crescente anche nelle PMI; entrambe le realtà hanno dedicato questi anni alla sperimentazione, alternando risultati promettenti a costosi fallimenti.