La Quarta Rivoluzione Industriale è fortemente caratterizzata dalla volontà di utilizzare al meglio il digitale non più soltanto per ottimizzare i processi di business, ma soprattutto per abilitare nuovi servizi data-driven per l’azienda. In questa nuova era di digitalizzazione, l’ecosistema IT è basato sulla centralità dei dati, considerati asset aziendali di prima classe, che possono essere riutilizzati per molteplici casi d’uso, sia operazionali sia analitici.
Massimizzare il valore estraibile dai dati offre diversi fattori di vantaggio competitivo, come potenziare i servizi offerti al cliente finale, garantire nuove insight, fare previsioni sull’andamento futuro del business sfruttando tecniche di analisi avanzate basate su intelligenza artificiale, migliorare l’integrazione tra i sistemi software tradizionali e le nuove applicazioni digitali (web e mobile), generare nuove opportunità di ricavi tramite la condivisione e la monetizzazione dei dati.
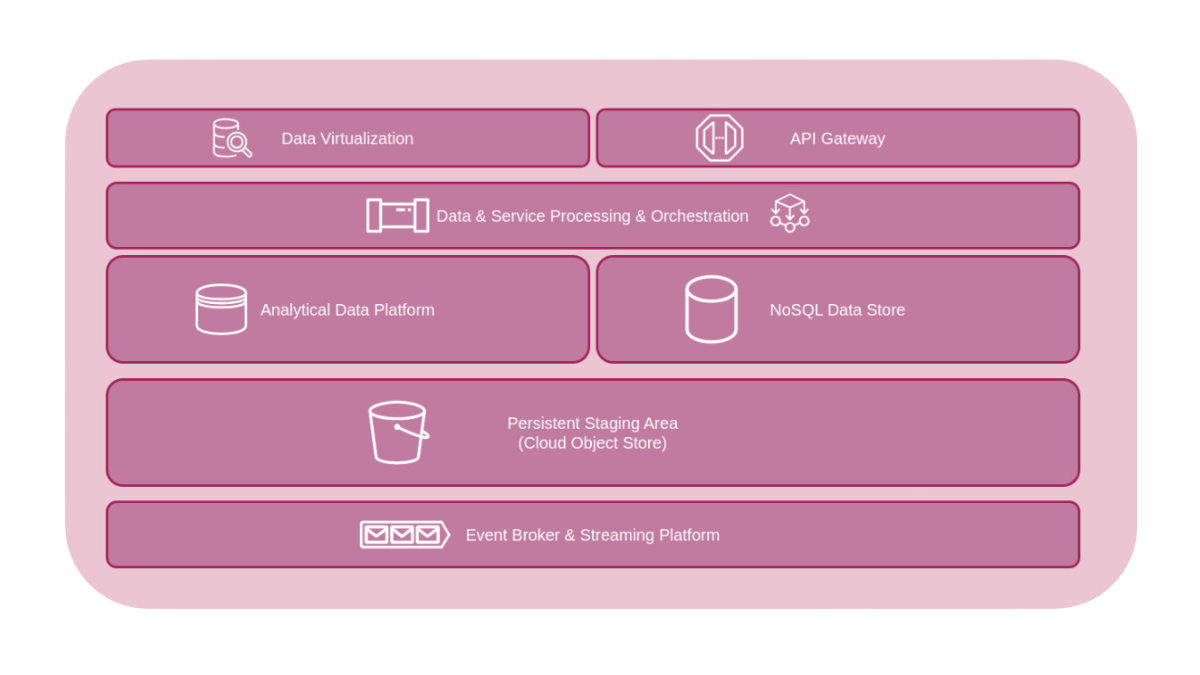
Per rendere possibile il raggiungimento di questi obiettivi è necessario dotarsi di una piattaforma di integrazione che faciliti l’accesso, la condivisione e l’utilizzo dei dati da parte di applicativi differenti da quelli che hanno generato i dati stessi. Un simile scenario rappresenta un punto di svolta rispetto al passato, in cui le architetture IT venivano progettate con un approccio che dava maggior centralità all’investimento nelle applicazioni di dominio (Systems Of Record), a discapito della gestione dei dati. L’integrazione di questi ultimi era considerato un aspetto secondario, da affrontare in modo prettamente funzionale ad abilitare i singoli casi d’uso che si presentavano, senza una vera e propria strategia di data management lungimirante. Le applicazioni erano progettate in un modo che non era orientato alla condivisione, ma alla conservazione dei dati al proprio interno: questo aspetto rendeva difficile e costoso il riuso dei dati come asset e limitava il valore estraibile da essi.
Il movimento data centrico sta contribuendo fortemente a cambiare il paradigma di pensiero e questo ha come conseguenza l’affermarsi di nuovi pattern architetturali che sono maggiormente in linea con i principi di condivisione e riuso dei dati rispetto a quanto lo fossero le piattaforme basate su integrazioni ETL punto a punto o architetture SOA tradizionali. Tra questi, il pattern Digital Integration Hub risulta essere particolarmente interessante per la sua capacità di sfruttare al meglio le tecnologie moderne e basate sul cloud al fine di rendere disponibile i dati di dominio a diversi consumatori in modo scalabile ed efficiente.